오늘 살펴 볼 논문은 2021년 ICCV에서 발표된 논문인 "SwinIR: Image Restoration Using Swin Transformer" [1] 이다.
SwinIR은 2022년 3월 현재 PapersWithCode 웹사이트 기준 Set5, Set14 데이터셋에서 1위를 차지하고 있다.
https://paperswithcode.com/task/image-super-resolution
Papers with Code - Image Super-Resolution
In this task, we try to upsample the image and create the high resolution image with help of a low resolution image.
paperswithcode.com
SwinIR은 동일한 해인 2021년 ICCV에서 발표된 논문인 "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" [2] 의 아카이브 버전 공개 당시 해당 Swin Transformer 구조를 SISR 문제 해결에 활용하였다.
본문으로 들어가기에 앞서, 본 논문에서는 다양한 태스크에 대하여 실험을 보이고 있으며 본 글에서 언급하는 정의된 값들은 'Classical image SR' 태스크에 해당함을 참고바란다.
Network Architecture
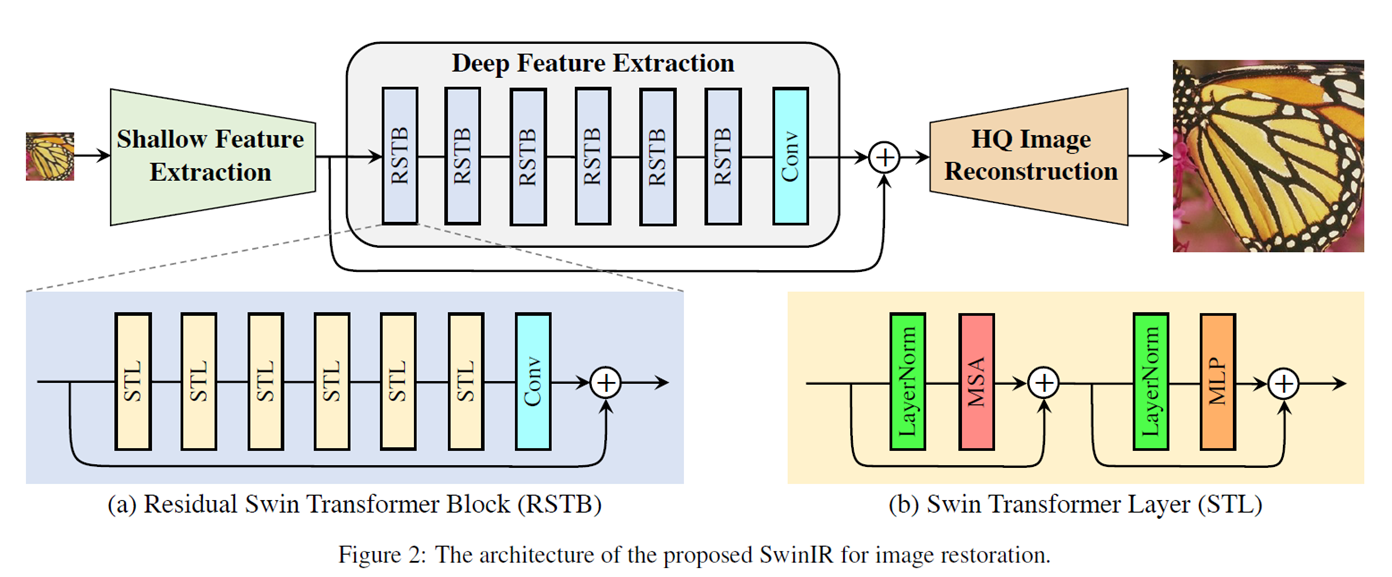
SwinIR의 전체적인 구조는 세 개 부분으로 나눌 수 있다.
- Shallow Feature Extraction
1개의 Conv layer (number of feature : 3 -> 180)
- Deep Feature Extraction
Based on Residual Swin Transformer Block
- HQ Image Reconstruction
Conv layer -> Depth-to-Space -> Conv layer
Shallow Feature Extraction는 1개의 Conv layer를 통해 feature 개수를 늘린다.
즉, 이미지를 embedding 시키는 역할을 한다고 볼 수 있으며, 본 논문에서는 feature 개수를 180으로 지정하였다.
Deep Feature Extraction은 Residual Swin Transformer Block (RSTB)에 기반한 Deep한 네트워크이며, 본 논문의 핵심이다.
6개의 RSTB를 거친 후, Conv layer 1개를 거친 출력에 원본 feature (Shallow Feature Extraction 모듈의 출력) 를 더한다.
HQ Image Reconstruction은 모든 Feature Extraction 과정이 끝난 후, 기본적인 SR을 위한 Reconstruction에 맞게 구조화되어 있다. 즉, Conv layer를 통해 원하는 크기의 출력 사이즈에 맞게 feature 개수를 조정하고, Depth-to-Space를 수행 한후, Conv layer를 통해 최종 이미지를 출력한다.
Deep Feature Extraction
- Residual Swin Transformer Block (RSTB)


각각의 RSTB는 6개의 Swin Transformer Layer (STL) 를 거친 후, Conv layer 1개를 거친 출력에 현재 RSTB의 첫 입력 feature를 다시 더해주는 구조를 가진다.
- Swin Transformer layer (STL)

각각의 STL은 위와 같은 구조를 가진다.
본 글에서는 Normalization이나 Drop out 같은 부수적인 부분들은 설명에서 생략하고, 핵심 모듈들을 소스코드 관점 순서에 맞게 설명을 하도록 하겠다.
각 STL에서는 우선 Window Shift를 수행한다.
해당 부분의 피규어는 Swin Transformer 제안 논문 [2] 에서 가져와 설명하도록 하겠다.

위 그림처럼, 이미지는 x축, y축 각각에 대해 shift 된다.
SwinIR은 window size를 8x8로 지정하고 있으며, shift 크기는 [-(window_size//2), -(window_size//2)] 만큼 수행되어 결국 [-4, -4]만큼 shift된다.
또한, regular(shift를 수행하지 않음)와 shift를 번갈아가면서 수행하는 구조를 가지는데, SwinIR은 6개의 STL 레이어 중 0,2,4 번째 레이어는 regular, 1,3,5번째 레이어는 shift를 수행한다.
attention을 완료한 이후에 reverse shift를 통해서 원래 자리로 되돌려 놓는다. ([4, 4] 만큼 shift한다는 의미)
이 후, window partition을 수행한다.
그러므로, feature의 shape은 아래와 같은 순서로 변환된다.
[B, H, W, C] (=[Batch, Height, Width, numberOfFeature(180)]
-> [numberOfWindow*B, window_size, window_size, C]
-> [numberOfWindow*B, window_size*window_size, C] = ([numberOfWindow*B, 8*8, 180])
참고로, 원래의 Swin Transformer의 제안 논문에서는 window merge 구조도 포함되어 있는데 SwinIR은 해당 방법은 수행하지 않는 것으로 보인다.
그런 후에 실제 Window Attention이 수행된다.
이는 원래의 Transformer 논문 [3] 에서 제안된 Multi-Head Attention 구조를 거의 그대로 따른다.

Attention 입력의 shape은 위에서도 언급했듯이 아래와 같다.
[numberOfWindow*B, window_size*window_size, C]
이를 더 간단히 표현하기 위해,
B_ : numberOfWindow*B
N : window_size*window_size (8*8)
C : 180
라고 하겠다.
Multi-Head Attention은 Self-Attention 구조이며, 따라서 동일한 feature Q(Query), K(Key), V(Value)가 활용된다.
그러면 결국 여기에서는 Q, K, V 각각 [N, C] Matrix를 가지게 된다.
우선, Shape이 아래와 같이 변경된다.
[B_, N, 3, 6(num_heads), C // 6(num_heads)] -> [3, B_, 6, N, C // 6]
본 논문에서는 head 개수를 6으로 지정하였으며, 위 feature를 3개로 분리하면 shape은 아래와 같다.
[B_, 6, N, C // 6]
Attention 수식은 아래와 같다.
우선, 본 논문에서는 d 값을 C//6으로 지정하고 있으며, B는 learnable relative positional encoding 값이다.
핵심적으로 보면, SoftMax(QK)V 라는 Self-Attention 구조를 가진다.이 때, Matrix shape을 분석해보면 아래와 같다.
QK = [64, 30] X [30, 64] = [64, 64] = [N, N]
Softmax(QK)V = [64, 64] X [64, 30] = [64, 30] = [N, C // 6]
Attention 이 후, Shape을 multi-head로 분리되어 있던 것을 하나로 합치기 위해 아래와 같이 변환한다.
[B_,6,N,C // 6] -> [B_,N,C]
이 후, FC 레이어를 거쳐 최종 출력을 반환하고, 다음 STL 로 들어간다.이 때 shape은 변하지 않는다.
Experiments


[References]
[1] Liang, Jingyun, et al. "Swinir: Image restoration using swin transformer." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[3] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
'Research > Super-Resolution' 카테고리의 다른 글
| [정리] Overview of Video Super-Resolution (VSR) (0) | 2023.03.07 |
|---|---|
| [논문 리뷰] Mutual Affine Network for Spatially Variant Kernel Estimation in Blind Image Super-Resolution (0) | 2022.05.09 |
| [논문 리뷰] Deep Unfolding Network for Image Super-Resolution (0) | 2022.03.02 |
| [논문 리뷰] Deep Blind Video Super-Resolution (0) | 2022.02.24 |
| [구현] Implementation of Lucas-Kanade Optical Flow Method (0) | 2022.02.23 |