오늘 살펴 볼 논문은 2020년 CVPR에서 발표된 논문인 "Deep Unfolding Network for Image Super-Resolution" [1] 이다.
해당 논문은 "Deep Blind Video Super-Resolution" [2] 이라는 논문의 latent frame restoration 파트 (MAP 프레임워크를 통해 HR 이미지를 추론하는 데 있어서 FFT 기반의 수식을 이끌어냄) 의 기반이 된 논문이라 할 수 있다.
논문 제목에 맞게 '펼치다' 라는 의미를 담고 있는 unfolding 알고리즘을 통해 data term, prior term 두 가지 sub-problem을 해결하는 문제로 변환하였다는 점이 이 논문의 핵심이며, 실제 딥러닝 모델이 활용되는 부분은 prior term과 관련이 있다.
이 논문은 기존의 model-based SR 기법을 다양한 scale factor, blur kernel, noise level을 사용하여 end-to-end learning-based SR 모델에 효과적으로 결합한 연구라고 볼 수 있다.
1) Unfolding optimization
MAP (Maximum a posteriori)에 기반하여 이미지 degradation model은 아래와 같이 정의 할 수 있다.
(y : LR image, x : HR image, k : blur kernel, s : scale factor, λ : trade-off parameter)

위 수식은 data term과 prior term으로 이루어져 있다.
본 논문에서는 두 가지를 분리하여 sub-problem으로 변환하기 위해 half-quadratic splitting (HQS) 알고리즘을 적용하였으며, 그렇게 변환한 수식은 아래와 같다.


여기서 z 라는 보조 변수를 사용하였으며, 수식 (5)와 (6)을 반복적으로 계산함으로써 최소화시키는 문제로 변환된다.
결론적으로, z를 계산하는 수식은 data term을 담고 있으며 계산된 z를 x를 계산하는 식에 넣어 최종 HR x를 얻는 방식을 가진다. 참고로 여기서의 z와 x에 붙어있는 k는 iteration을 의미한다.
우선, 수식 (5)는 z에 대하여 미분한 결과를 0과 같다고 두어 문제를 풀 수 있다.
blur kernel k를 H라는 matrix로 두었을 때, 미분한 결과는 아래와 같다.

이 때, 두 개의 방정식 A와 B가 있다고 할 때, AXB=FFT^-1(FFT(AXB)) 라는 특성을 반영하여 아래와 같이 FFT 기반의 식을 얻을 수 있다.
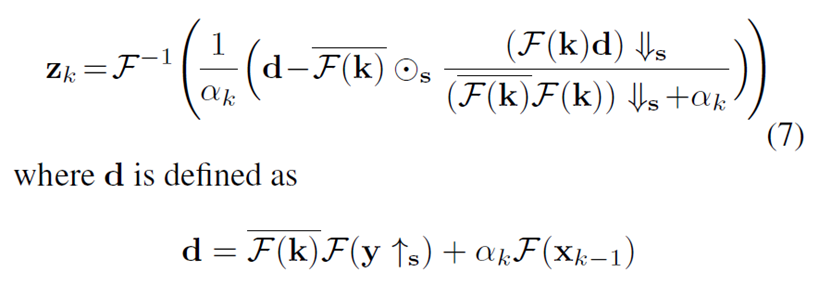
이 때 알파는 μ_k*σ^2 과 같고, 해당 값은 HR을 얻기 위한 수식을 통제할 수 있다.
다음으로, 수식 (6)은 아래와 같이 다시 쓸 수 있다.

위 수식을 해석하면, 입력 이미지 z를 잡음 레벨 √(λ/μ) 에 해당하는 가우시안 잡음 제거기에 통과시킨 결과와 같다고 할 수 있다.
본 논문에서는 이러한 잡음 레벨 √(λ/μ) 을 베타로 둔다.
2) Deep unfolding network

본 논문에서 제안하는 네트워크는 크게 3가지 모듈로 구성되어 있다.
- D : data module
- P : prior module
- H : hyper-parameter module
우선, H 모듈은 node level과 scale factor 를 입력으로 받아 (size 2 벡터) iteration 수 (본 논문에서는 8) 만큼의 알파, 베타를 (size 2*8 벡터) 출력으로 낸다.
H는 3개의 FC 레이어로 이루어져 있음.
D 모듈은 앞에서 언급한 FFT 기반의 수식을 통해 z를 출력함.
P 모듈은 U-Net[3]에 residual block을 결합한 ResUNet 구조로 설계됨. 즉, 이는 denoising을 위한 모듈이 됨.
3) Experiments
본 논문에서 사용하는 scale factor, blur kernel, noise level :
- s : {2, 3, 4}
- K : they only consider 12 representative and diverse blur kernels, including 4 isotropic Gaussian kernels with different widths (i.e., 0.7, 1.2, 1.6 and 2.0), 4 anisotropic Gaussian kernels, and 4 motion blur kernels.
- σ : {0, 2.55, 7.65}


실험 결과, 기존 연구들과 비교하여 PSNR이 전체 실험에서 가장 높은 결과를 보이고 있으며,
비주얼적으로 봐도 다른 연구들보다 더 섬세한 디테일을 잘 살리고 있다.
또한, 본 논문에서 추가적으로 실험한 USRGAN 결과가 PSNR은 USRNet보다 떨어지더라도 비주얼적인 결과는 가장 좋다.
[References]
[1] Zhang, Kai, Luc Van Gool, and Radu Timofte. "Deep unfolding network for image super-resolution." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[2] Pan, Jinshan, et al. "Deep blind video super-resolution." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[3] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
'Research > Super-Resolution' 카테고리의 다른 글
| [논문 리뷰] Mutual Affine Network for Spatially Variant Kernel Estimation in Blind Image Super-Resolution (0) | 2022.05.09 |
|---|---|
| [논문 리뷰] SwinIR: Image Restoration Using Swin Transformer (0) | 2022.03.08 |
| [논문 리뷰] Deep Blind Video Super-Resolution (0) | 2022.02.24 |
| [구현] Implementation of Lucas-Kanade Optical Flow Method (0) | 2022.02.23 |
| [논문 리뷰] Lucas-Kanade Optical Flow Method (0) | 2022.02.23 |