오늘 살펴 볼 논문은 2021년 ICCV에서 발표된 논문인 "Deep Blind Video Super-Resolution" [1] 이다.
해당 논문은 1) 기존의 MAP (Maximum a posteriori) 기반의 많은 연구들이 직접 hand-crafted priors를 구해야 하기 때문에 문제를 해결하기에 복잡해 질 수 있으며, 2) 대부분의 딥러닝 기반의 VSR 모델들은 Blur kernel을 알고 있다는 가정하에 설계되었으므로 결과 이미지가 over-smoothed 될 수 있다는 단점을 가진다는 점을 들어 문제를 제기하였다.
따라서, 본 논문에서는 두 가지 방법을 모두 결합한 VSR 딥러닝 모델을 제안하였다.
1) Revisiting Variational Methods
제안하는 딥러닝 모델의 기반이 된 MAP 기반의 방법론을 먼저 살펴본다.
VSR을 위한 Degradation 모델은 아래와 같이 정의 할 수 있다.

위 수식에서, 각 notation이 의미하는 바는 아래와 같다.
L : LR images, I : HR frame, S : down-sampling matrix, K : blur kernel, F : warping matrix (u : optical flow), n : noise
즉, i번째 HR (High-resolution) 프레임에 optical flow에 의한 warping matrix가 곱해지고, blur kernel이 적용되고, down-sampling이 수행 된 후 noise가 가해지면 2N+1개의 LR (Low-resolution) 프레임들 (i-N~i+N)을 얻게 된다.
VSR 문제에서 주어진 LR 프레임들로부터 우리가 구하고자 하는 것은 HR 프레임, optical flow, blur kernel 이며 MAP에 기반하여 아래와 같이 표현 할 수 있다.

즉, Bayes' Rule에 의해 posterior를 maximize 하는 문제는 prior와 likelihood의 곱으로 구할 수가 있다는 것을 의미하며
이 때, 주어진 LR에 대한 prior를 의미하는 분모에 해당하는 값이 없는 이유는 분모는 Maximum 최적화 과정에서 소거가 되기 때문이다.
최적화하는 입장에서 위와 같은 maximize 하는 문제는 아래와 같이 minimize하는 문제로 바뀔 수 있다.

이렇게 변형 할 수 있는 이유는 구하고자 하는 값들은 실제로 알 수 없기 때문에 random variable이라 할 수 있는데,
그러므로 Gaussian 분포, Laplace 분포와 같은 분포를 따른다고 가정 할 수 있다.
likelihood를 의미하는 수식들은 두 가지 분포 어떤게 됐든 상수 값들은 모두 소거하고 log를 취하면 -가 붙은 (예측-정답)^2 혹은 |예측-정답| 형태의 수식을 얻을 수 있다. 이를 다시 말하면, Gaussian 분포를 따른다고 하면, L2 형태가 될 것이며, Laplace 분포를 따른다고 하면 위와 같은 L1 형태가 된다.
마지막으로, 앞에 -를 없애면 maximize 하는 문제가 minimize하는 문제로 변하게 된다.
또한, 마찬가지로 log를 취했으므로 각각의 prior들은 더해주는 형태로 남게 된다.
결과적으로, 모든 prior들을 hand-crafted 하게 정의했다고 가정 할 때, 위 수식들을 통해 HR 프레임, optical flow, blur kernel 각각에 대한 estimation 할 수 있다.
하지만, 앞에서도 언급했듯이 이러한 방법은 직접 hand-crafted priors를 구해야 하기 때문에 문제를 해결하기에 복잡해 질 수 있으며, non-convex objective function을 풀어야 하는 문제가 될 수 있기 때문에 한계를 가진다.
2) An overview of the proposed method

위 그림은 본 논문에서 제안하는 모델의 전체 구조를 나타낸다.
본 글에서는 전체 모듈의 부분들을 아래 순서대로 설명한다.
- Optical flow estimation (+Feature extraction, Feature warping and fusion)
- Blur kernel estimation
- Latent frame restoration
- Sharp feature extraction and HR frame restoration
3) Optical flow estimation (+Feature extraction, Feature warping and fusion)
본 논문에서 제안하는 모델의 optical flow estimation 모듈은 2018년 CVPR에서 발표된 논문 "PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume" [2] 에서 제안된 PWC-Net을 사용하였다.
optical flow estimation 네트워크는 논문 상에서 N_0로 표기하였다.
구한 optical flow map들은 입력 LR 이미지들에 warping을 수행하는 게 아닌, feature space에서 수행한다.
따라서, feature extraction 네트워크 N_e로부터 feature를 추출한 후 feature에 warping을 수행한다.
warped feature들은 concat 된 후 fusion 네트워크 N_f로 들어가 최종 warped feature H^f를 구할 수 있게 된다.
N_e와 N_f가 어떤 레이어들로 구성되어 있는 지는 위 전체 구조 그림을 참고 바란다.
4) Blur kernel estimation
본 논문에서 제안하는 모델의 핵심이라 할 수 있는 blur kenel estimation 파트는 몇 개의 Convolution layer, RCAB (Residual Channel Attention Block), Adaptive Average Pooling, FC layer, Softmax layer로 이루어져 있다.
blur kernel estimation 네트워크는 논문 상에서 N_k로 표기하였다.
이러한 레이어들을 거쳐 여기서 구하고자 하는 것은 blur kernel 이며,
기존 다른 VSR 딥러닝 모델에서 blur kernel을 bicubic 등으로 고정시키고 시작하는 것과 달리 본 논문에서는 실제로 blur kernel을 구하는 방식을 가지므로 더 정확하게 deblurring을 수행 할 수 있다.
본 논문에서는 kernel estimation의 정확도를 높이기 위해, 이를 위한 loss function을 추가적으로 아래와 같이 설계하였다.

이러한 loss function L_k는 아래와 같이 최종 loss function에 더해주는 형태로 사용된다.

5) Latent frame restoration
Blur kernel K를 구한 이후, K와 LR 프레임들을 통해 HR 프레임을 예측 할 수 있다.그러므로, 본 논문에서는 최종 HR 프레임을 구하기 앞서 draft한 HR 프레임을 아래 수식에 기반하여 예측하며, 이를 Intermediate latent HR frame 이라 부른다.
위 수식에서 HR 프레임의 이미지 prior에 해당하는 부분은 gradient operation 기반으로 정의한다.
또한, 위 수식은 FFT (Fast Fourier Transform)에 기반하여 아래와 같은 closed-form solution을 구할 수 있다.

위 수식을 통해 구한 값을 Intermediate latent HR frame 이라 한다.
6) Sharp feature extraction and HR frame restoration
앞에서 구한 warped feature H^f 와 latent HR frame을 사용하여 최종적으로 HR 프레임을 추론한다.
우선, latent HR frame은 아래와 같이 sharp feature extraction 네트워크 N_d를 통과한다.
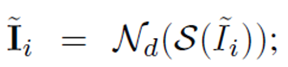
이 때, warped feature H^f와 HxW shape을 맞춰주기 위해 space-to-depth operation (S) 을 통해 HR 크기를 다시 LR 크기로 변형시키고, Convolution layer와 LeakyReLU로 이루어진 N_d 네트워크를 통과한다.
그리고, 본 논문에서는 sharp feature transform을 affine transformation에 기반하여 설계하였는데 그 수식은 아래와 같다.

즉, affine transformation과 같이 ax+b와 같은 형태를 가지도록 설계되었으며 곱해주는 matrix와 더해주는 matrix 각각을 각각의 convolution layer를 통해 구한다.
모델의 전체 구조를 보면, 최종 HR frame restoration 네트워크에서도 sharp feature extraction이 반복적으로 삽입되어 있음을 확인 할 수 있다.
또한, 최종적으로 up-sampling을 하는 부분은 PixelShuffle 함수를 활용하고 있음을 확인 할 수 있고, 마지막에 LR 프레임에 Bilinear up-sampling을 적용하여 출력부에 더해줌으로써 global하게 residual learning을 수행하고 있음을 알 수 있다.
7) Implementation
구현에 있어서 중요한 부분 하나만 언급하고 가자면,
본 논문에서는 optical flow estimation network를 pre-trained model로 초기화를 시키며,
blur kernel estimation network의 경우 먼저 학습을 따로 수행 한 후 해당 pre-trained model을 활용하여 전체 네트워크를 학습시키는 구조를 가진다.이 두가지 네트워크를 제외한 나머지 네트워크들은 lr 0.0001로부터 시작하고, 두 네트워크는 이미 학습이 진행된 바 있으므로 lr 0.000001로부터 시작한다.
8) Experimental Results
결과적으로, 기존 VSR SOTA 모델들보다 높은 PSNR, SSIM 값을 얻을 수 있고, 비주얼적으로도 더 sharp한 특징이 강조된 결과를 보인다.

[References]
[1] Pan, Jinshan, et al. "Deep blind video super-resolution." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Sun, Deqing, et al. "Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
'Research > Super-Resolution' 카테고리의 다른 글
| [논문 리뷰] SwinIR: Image Restoration Using Swin Transformer (0) | 2022.03.08 |
|---|---|
| [논문 리뷰] Deep Unfolding Network for Image Super-Resolution (0) | 2022.03.02 |
| [구현] Implementation of Lucas-Kanade Optical Flow Method (0) | 2022.02.23 |
| [논문 리뷰] Lucas-Kanade Optical Flow Method (0) | 2022.02.23 |
| [논문 리뷰] Understanding Blind Deconvolution Algorithms (0) | 2022.02.23 |