오늘 살펴 볼 논문은 2021년 VCIP에서 발표된 논문으로, 제목은 'Video Compression based on Jointly Learned Down-Sampling and Super-Resolution Networks' [1] 이다.
down-sampling과 super-resolution 기반의 video coding 논문이며 앞서 리뷰한 논문인 'RR-DnCNN v2.0: Enhanced Restoration-Reconstruction Deep Neural Network for Down-Sampling-Based Video Coding' [2] 를 비교 논문으로 하여 실험 결과를 낸 바가 있어 리뷰해보려고 한다.
RR-DnCNN v2.0 논문에 대한 리뷰는 아래 글을 참고바란다.
[논문 리뷰] RR-DnCNN v2.0: Enhanced Restoration-Reconstruction Deep Neural Network for Down-Sampling-Based Video Coding
오늘 살펴 볼 논문은 'RR-DnCNN v2.0: Enhanced Restoration-Reconstruction Deep Neural Network for Down-Sampling-Based Video Coding' 라는 제목으로 2021년 IEEE Transactions on Image Processing에 실린 논..
young-square.tistory.com
Introduction
최근 제안된 많은 딥러닝 기반의 super-resolution (SR) 모델을 활용한 down-sampling-based video coding 연구들은 bicubic과 같은 predefined down-sampling을 사용하기 때문에 low-resolution (LR) 프레임을 adaptive하게 얻을 수 없다.
또한, down-sampling-based video coding의 기본 구조를 생각해보면, 만약 down-sampling과 up-sampling을 각각 network를 구성하여 학습시킨다고 할 때, 이들 사이에 코덱의 인코딩, 디코딩 모듈이 위치해있고 코덱 모듈은 non-differentiability하다. 즉, 코덱 모듈로는 back-propagation을 할 수 없다.
이러한 경우, down-sampling과 up-sampling을 함께 joint 하여 optimization을 하기에 어려움이 있다.
본 논문에서는, 딥러닝 기반의 down-sampling network를 설계 및 학습시키고 virtual codec network를 설계 및 학습하여 위 두 가지 문제를 해결했다.
Proposed Method

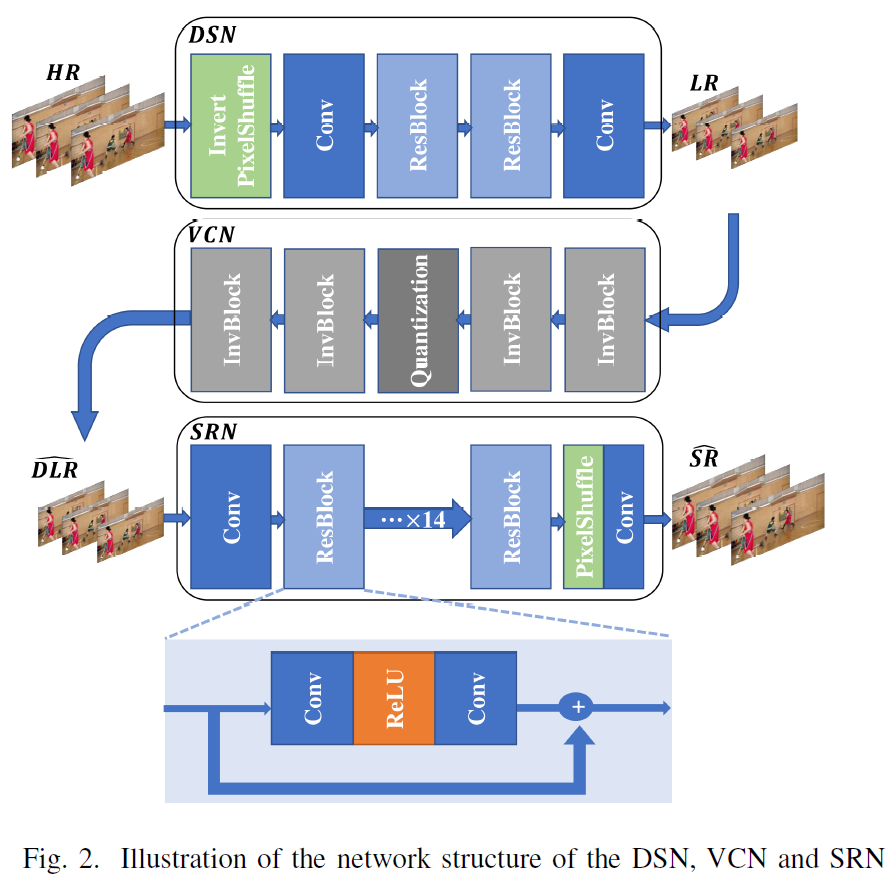
위 그림은 본 논문에서 제안하는 모델의 전체 구조를 보여준다.
high-resolution (HR) 프레임이 down-sampling network (DSN) 을 통해 low-resolution (LR) 프레임이 되며,
이 LR 프레임은 인코더와 디코더를 거쳐 압축에 의한 손실이 발생한 reconstructed LR이 된다.
Inference 단계에서는 이렇게 얻은 decoded LR (DLR)이 super-resolution network (SRN)의 입력으로 들어가 SR 프레임을 생성하지만,
Training 단계에서는 코덱에서 끊기지 않고 end-to-end로 DSN과 SRN을 학습시키기 위해 virtual codec network (VCN)을 구축해 기존의 코덱을 대체하도록 구성했다.
이 때, 학습의 안정화를 위해 VCN은 DSN+SRN과 번갈아가며 파라미터를 업데이트 시켜 학습시켰다. 즉, DSN+SRN을 학습시킬 때는 VCN의 파라미터를 고정시키고, VCN을 학습 시킬 때는 DSN+SRN의 파라미터를 고정시켰다.
기존 비디오 코덱에서는 기본적으로 최적의 모드를 결정하기 위해 rate distortion (RD) cost를 계산해 optimization 시키는 방식을 사용한다.
여기서 rate는 bitrate를 의미하고 distortion은 원본과 복원된 영상의 차이를 나타내므로 픽셀 기반의 에러값이라고 생각하면된다. 따라서, 데이터의 양과 화질의 trade-off를 고려하여 모드를 결정짓는다고 이해하면 된다.
본 논문에서는 현재 풀고자 하는 문제도 아래와 같은 RD function으로 표현했다.
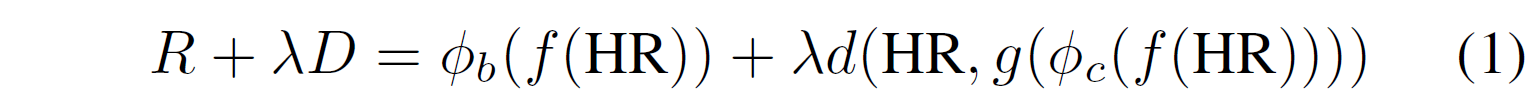
여기서, f()는 DSN, g()는 SRN을 나타낸다.
본 논문에서는, 앞에서도 언급했듯이 코덱을 virtual하게 대체하여 학습시킬 수 있도록 하면 모델을 전체적으로 joint하여 학습시킬 수 있으므로 위 수식을 아래와 같이 대체한다.

각 네트워크에 대한 구조는 아래 그림과 같다.
여기서 Invert Pixelshuffle은 Space-to-Depth 연산을 말하는 것이며,
SRN은 EDSR [3] 베이스라인 구조를 활용했다.
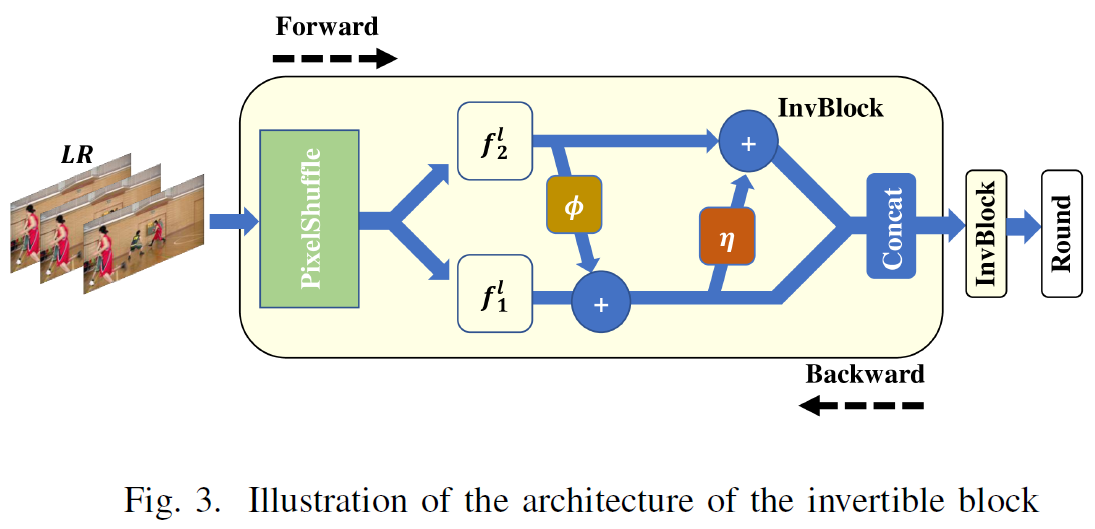
VCN의 InvBlock 구조는 아래와 같다.
위 그림에서 앞 InvBlock 2개는 Forward, Quantization은 Round, 뒤 InvBlock 2개는 Backward라고 보면 되며, 간략하게 인코딩, 디코딩 구조를 표현한 것이라고 이해 할 수 있다.
참고로, 그림을 PixelShuffle로 표현했지만, 개인적으로 뒤에서 f1, f2로 feature channel level에서 나눈다는 점에서 Invert PixelShuffle이라고 해석하는 게 더 맞을 것 같다.
아래 그림의 내부 구조는 수식 (3), (4)에서 동일하게 표현하고 있다. 전제적으로 affine transformation 구조를 이루고 있다.
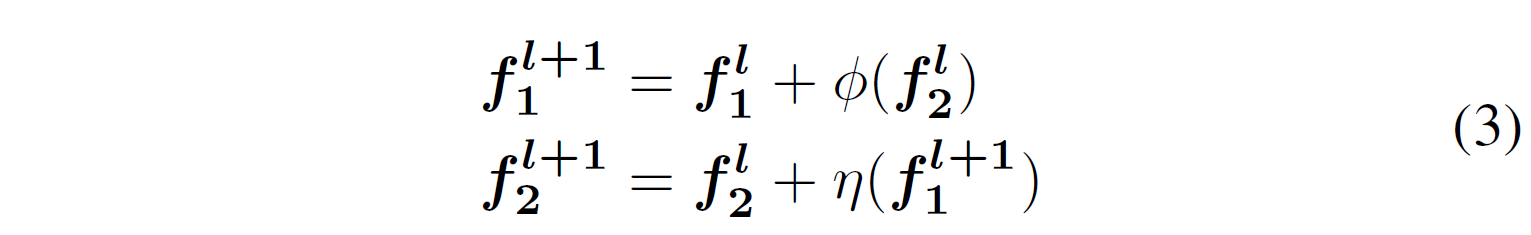

본 논문에서 구조화한 loss function은 아래와 같다. 우선, distortion을 맡고 있는 loss function은 수식 (5)와 같다. 실제 codec, virtual codec에 의한 결과물 각각에 대하여 MSE함수 기반의 loss를 구해 더해준 형태이다.

rate를 맡고 있는 loss function은 수식 (6)와 같다. 이러한 bitrate loss를 위해서는 estimated entopy of LR을 구하는 방식으로 활용한다고 한다.
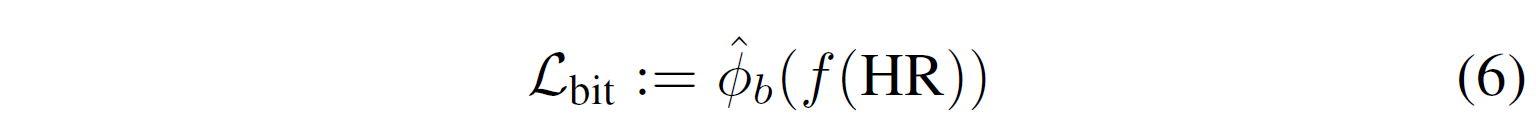
또한, regularization term으로써 아래 수식 (7)을 활용한다. 즉, 일반적인 bicubic에 의해 생성된 LR과 DSN을 통해 생성된 LR 사이의 loss를 구한다.

위에서 언급한 모든 loss들을 각각의 weight를 사용하여 더하여 최종 loss function을 구성한다.

추가적으로, 앞에서 언급한 바 있듯이 VCN은 개별로 학습되므로 아래와 같은 개별 loss function을 구성한다.
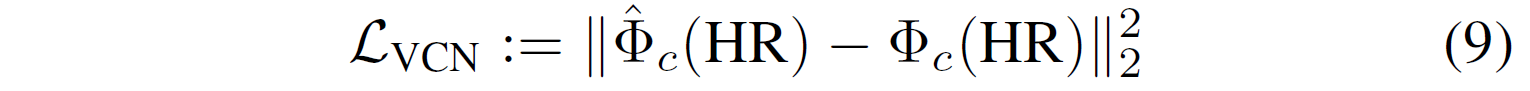
Experiments
사용된 HEVC 버전은 16.20이며,
All Intra (AI), QP 37로 세팅하여 학습 데이터를 만들어 학습시켰다.
이 때 학습에 사용된 데이터셋은 Vimeo-90k 이다.
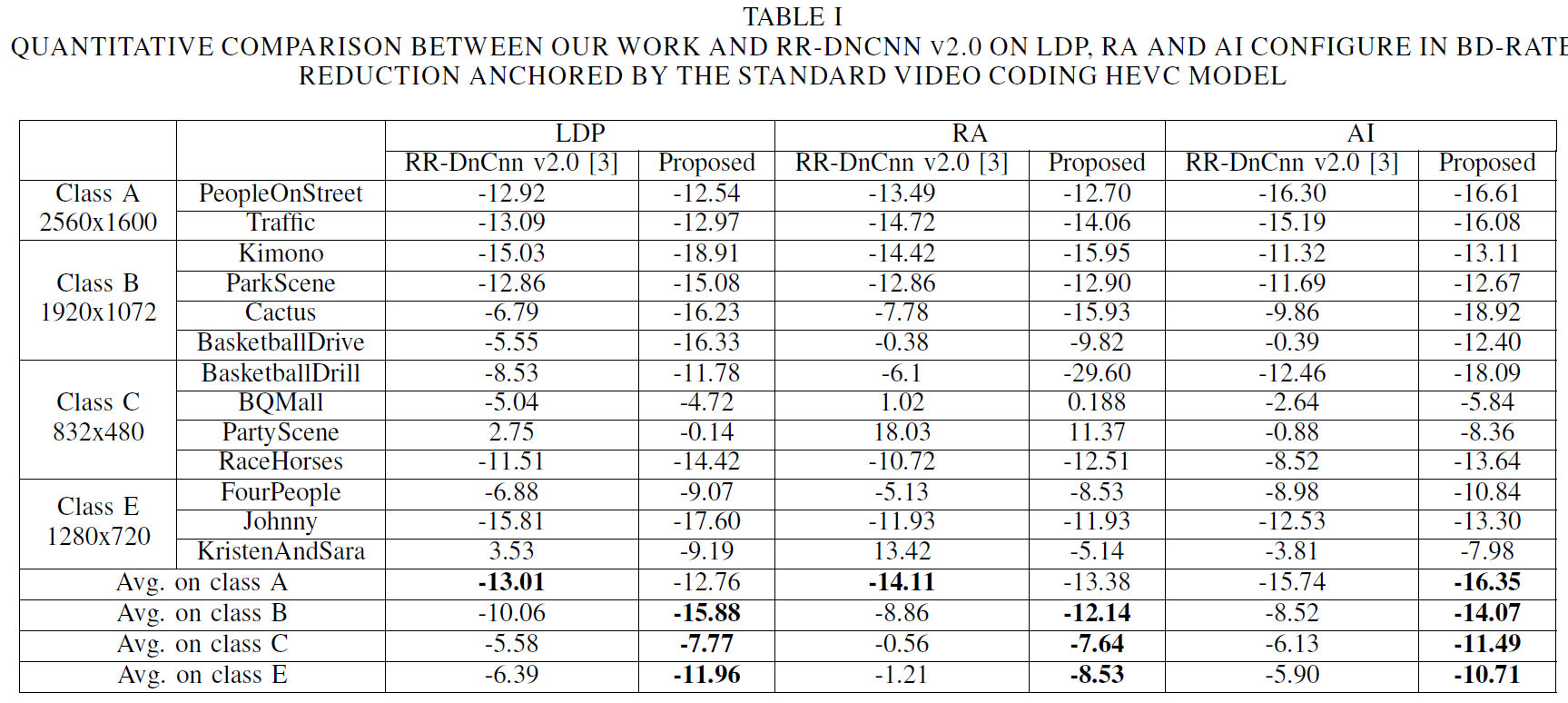
논문에 삽입된 결과는 A, B, C, E CTC 시퀀스 클래스에 대한 결과이며, 사용된 QP range는 {32, 37, 42, 47} 이다.
또한, Y에 대한 결과만 보여주고 있다.
아래 표를 보면, RR-DnCnn v2.0과 비교하여 LDP와 RA의 A 클래스를 제외한 나머지 모든 클래스에서 더 좋은 BD-rate 결과를 보이고 있음을 확인 할 수 있다.
References
[1] Wei, Yuzhuo, Li Chen, and Li Song. "Video Compression based on Jointly Learned Down-Sampling and Super-Resolution Networks." 2021 International Conference on Visual Communications and Image Processing (VCIP). IEEE, 2021.
[2] Ho, Man M., Jinjia Zhou, and Gang He. "RR-DnCNN v2. 0: enhanced restoration-reconstruction deep neural network for down-sampling-based video coding." IEEE Transactions on Image Processing 30 (2021): 1702-1715.
[3] Lim, Bee, et al. "Enhanced deep residual networks for single image super-resolution." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017.