[논문 리뷰] RR-DnCNN v2.0: Enhanced Restoration-Reconstruction Deep Neural Network for Down-Sampling-Based Video Coding
오늘 살펴 볼 논문은 'RR-DnCNN v2.0: Enhanced Restoration-Reconstruction Deep Neural Network for Down-Sampling-Based Video Coding' 라는 제목으로 2021년 IEEE Transactions on Image Processing에 실린 논문 [1] 이다.
해당 논문은 동일 저자들이 2020년 Springer MultiMedia Modeling 에 출판한 'Down-sampling based video coding with degradation-aware restoration-reconstruction deep neural network' 라는 제목의 논문 [2] 을 개선한 version 2 연구라고 볼 수 있다.
Introduction
Video coding에 있어서 핵심은 bitrate를 최대한 줄이면서 화질적인 퀄리티는 유지하는 것이다.
따라서, down-sampling 기반의 video coding은 bitrate를 크게 줄일 수 있으므로 전체 코딩 효율에 큰 기여를 할 수 있다.
다시 말해, 만약 1920x1080 해상도의 영상을 960x540 해상도의 영상으로 down-sampling 시킨다면, 영상 자체의 크기를 단순히 생각했을 때 비트를 기존의 약 4분의 1 정도로 줄일 수 있으므로 그 차이는 매우 크다.
이러한 장점을 기반으로, 많은 down-sampling 기반의 video coding 연구들이 활발히 진행 중에 있으며 해당 논문 또한 그 중 하나이다.
하지만, down-sampling을 수행하게 되면 당연하게도 손실되는 화소 데이터가 많다.
이렇게 너무 많은 손실이 발생하면, 원본으로 되돌리기 훨씬 어려워지므로 결국 영상의 화질이 크게 저하될 수 밖에 없는데
비트를 아무리 많이 줄이더라도 화질 저하가 그만큼 크면 bitrate와 dirtortion 사이의 tradeoff를 고려해보았을 때 오히려 전체 코딩 효율이 떨어질 수 있다.
따라서, 딥러닝 기반의 super-resolution (SR) 기법을 적용해 up-sampling 단계에서 저하된 화질을 개선하면서 해상도를 높일 수 있도록 많은 연구들이 최근 진행되고 있다.
아래 그림은 이러한 연구들의 기본 구조를 표현하고 있다.
원본 영상을 down-sampling 한 후 기존 표준 코덱을 통해 encoding, decoding을 수행한다.
decoding 이후에 얻은 decoded low-resolution (DLR)은 기본적인 bicubic, bilinear을 사용하여 up-sampling 될 수 있지만,
화질을 더 개선하기 위하여 최근 이 과정에 딥러닝 기반의 super-resolution 모델을 적용한다.
최종적으로, 원본 해상도와 동일한 reconstructed 영상을 얻을 수 있다.
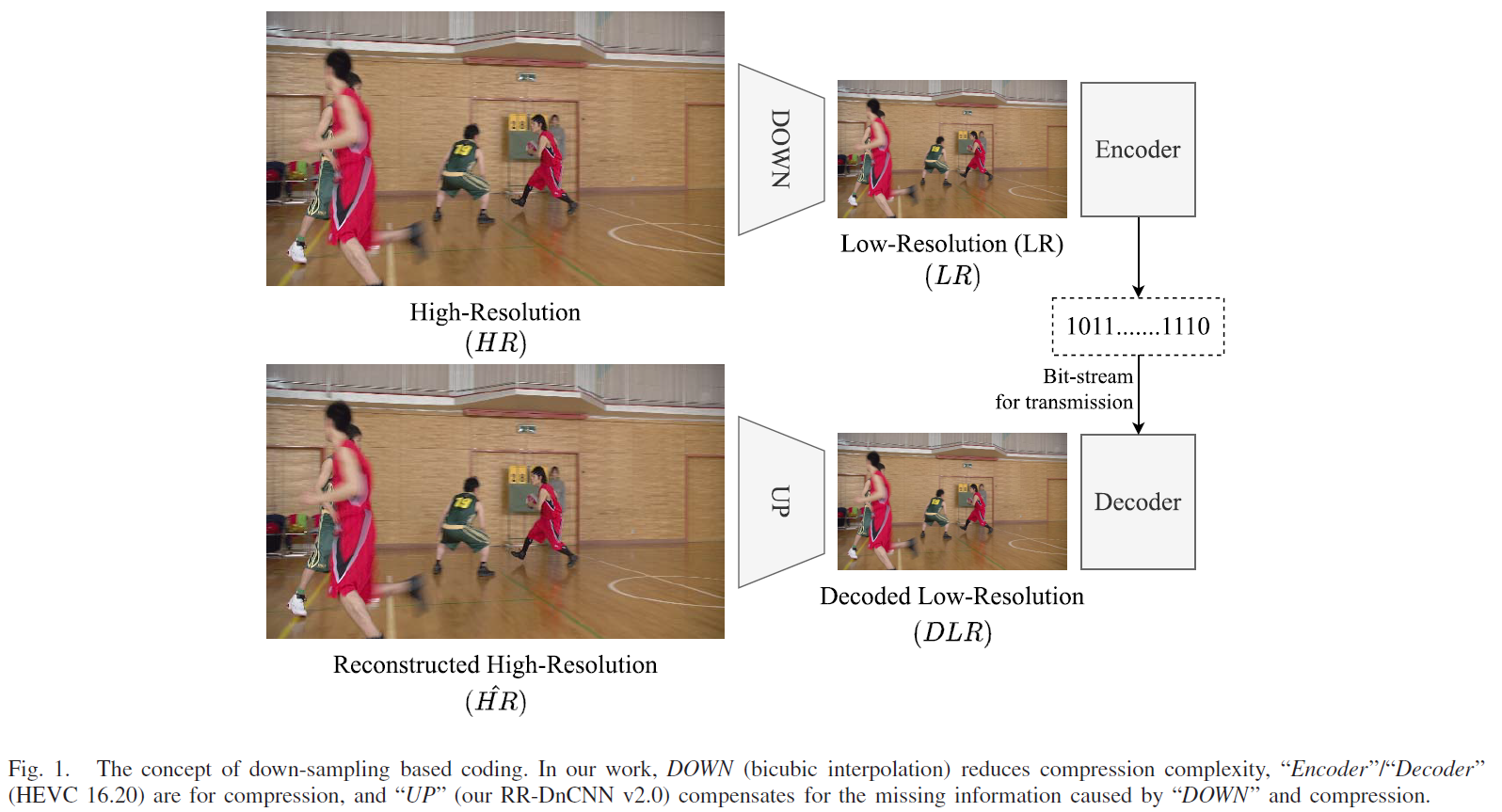
Proposed Video Coding System
해당 논문에서 제안한 RR-DnCNN v2.0의 모델 구조는 아래와 같다.

모델 구조를 보면, 크게 Restoration Network, Reconstruction Network 두 개 파트로 나뉜다.
일반적인 SR과는 다르게, video coding을 위한 SR은 풀어야 하는 문제가 좀 더 복잡해진다.
이말은 즉, down-sampling에 의해 발생한 degradation만 고려할 것이 아닌 compression에 의한 degradation까지 풀어야 할 숙제가 된다.
그러므로 이러한 compression degradation을 어떻게 해결하는 지가 관련 연구의 핵심이라 할 수 있는데
본 논문에서 제안한 모델은 restoration에서 compression degradation을 해결하고, reconstruction을 통해 SR을 수행한다.
우선, bicubic interpolation을 통해 high-resolution (HR) 을 down-sampling하여 low-resolution (LR)을 만든다.
LR은 기존 표준 HEVC 인코더, 디코더를 거쳐 decoded LR (DLR)이 되고,
DLR은 Restoration network에 들어가 compression에 의한 missing information을 restore 할 수 있도록 학습된다.
본 논문에서는 up-sampling skip-connection 을 통해 restoration의 hidden feature 들을 Reconstruction network에 전달하여 더하도록 구조화하였으며 이러한 구조는 U-Net [3] 으로부터 영감을 받았다고 한다.
아래 그림은 각각의 up-sampling skip-connection이 어떻게 이루어지고 있는지를 보여주고 있으며 feature를 up-sampling 시킬 때는 deconvolution을 사용한다.

전체 구조를 수식으로 표현하면 아래와 같다.
h는 본 논문에서 제안한 RR-DnCNN v2.0을 말하며, Rres, Rrec은 각 network의 output residual을 말한다.



RR-DnCNN v2.0은 restoration net, reconstruction net 두 모듈의 output에 대한 MSE를 더한 Loss function을 사용하여 학습된다. 즉, restoration을 통해 개선된 LR과 원본을 bicubic을 통해 down-sampling 시킨 LR 사이의 MSE와 최종 reconstructed HR과 원본 HR 사이의 MSE를 아래 수식에 따라 더하여 활용한다.

실험적으로, 알파=0.5 , 베타=0.05 로 설정했다고 한다.
Experiments
우선, 아래 표를 보면 학습 데이터를 3가지 각각의 configuration 기반으로 만들고 이를 각각 테스트 해본 결과를 보여주는데 결과는 흥미롭다.
일반적으로 3가지 각각의 특징이 다르므로 (특히, AI의 경우 I-Slice만으로만 구성되어 있으므로) 학습데이터와 테스트데이터를 다르게 사용할 경우 좋지 않은 결과를 보일 것이라 예상하지만 아래 결과를 보면 사실 그 차이가 그렇게 크지 않다.
이 점이 우선 주목할만한 점이라 생각한다.
데이터를 굳이 따로 만들지 않아도 한가지 configuration 만으로도 충분히 커버 가능하다는 것을 보여주는 것이기 때문이다.
결과를 더 자세히 살펴보면, 학습 데이터로 RA를 사용했을 때 RA와 AI에서 가장 높은 성능을 보인다는 것을 통해 AI의 경우에도 AI만으로 학습시키기보다는 좀 더 다양한 경우의 수가 있는 RA로 학습을 시키는게 그 차이가 크진 않지만 더 효과적이라는 것을 알 수 있다.
LDP의 경우, 나머지 두 개에서 worst 결과를 보이는 것으로 보아 LDP 자체에 최적화 되어 있다는 것을 확인 할 수 있다.결론적으로, 이러한 실험을 통해 본 논문에서는 RA만으로 학습 데이터셋을 구축하여 학습시켰다.

RR-DnCNN v2.0은 아래와 같은 two stage training 과정을 통해 학습되었다. 즉, CTC Sequence로 표현하자면 D 클래스 크기의 영상들로 학습 시킨 후 best model로 초기화하여 B 클래스 크기의 영상들로 Fine-tunning 시키는 방식을 택했다.
1) First stage :
- CIF (352x288) 크기의 영상 34개 (18,478 frames) 로 구성된 Xiph Video Test Media + 416x240 크기를 352x288로 resize한 CTC D class 영상 (1,912 frames)
- HR : 352x288
- LR : 176x144
2) Second stage
- Fine-tune the best model from the first stage
- UHD (3840x2160) 크기를 1920x1152 크기로 down-sampling한 영상 11개 (3,300 frames) 로 구성된 SJTU
- HR : 1920x1152
- LR : 960x576
아래 표를 보면, two stage training을 수행 했을 때 더 높은 결과를 얻을 수 있음을 확인 할 수 있다.
그리고, 본 연구에서는 Adam 대신 RAdam을 optimizer로 사용했고 더 높은 성능을 얻었다.

아래 표 2개는 RA, LDP, RA 각각에 대하여 BD-rate를 비교한 것을 보여주며
이 때 '[3]' 연구는 compression degradation을 고려하지 않은 MISR 모델을 나타내고,
'[2]'와 '[4]' 연구는 down-sampling 기반의 video coding을 intra prediction에 맞게 제안한 연구들을 나타낸다.
'[2]' Y. Li et al., “Convolutional neural network-based block up-sampling for intra frame coding,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 9, pp. 2316–2330, Sep. 2018, doi: 10.1109/TCSVT.2017.2727682.
'[3]' J. Lin, D. Liu, H. Yang, H. Li, and F. Wu, “Convolutional neural network-based block up-sampling for HEVC,” IEEE Trans. Circuits Syst. Video Technol., vol. 29, no. 12, pp. 3701–3715, Dec. 2019.
'[4]' Y. Li, D. Liu, H. Li, L. Li, Z. Li, and F. Wu, “Learning a convolutional neural network for image compact-resolution,” IEEE Trans. Image Process., vol. 28, no. 3, pp. 1092–1107, Mar. 2019, doi: 10.1109/TIP.2018.2872876.
기존 제안된 연구들과 비교하였을 때, RR-DnCNN v2.0이 특히 A클래스에서 좋은 성능을 보임을 알 수 있으며 RA C클래스를 제외하고 모든 시퀀스에서 평균적으로 HEVC Anchor와 비교하여 BD-rate gain을 얻고 있음을 확인 할 수 있다.


References
[1] Ho, Man M., Jinjia Zhou, and Gang He. "RR-DnCNN v2. 0: enhanced restoration-reconstruction deep neural network for down-sampling-based video coding." IEEE Transactions on Image Processing 30 (2021): 1702-1715.
[2] Ho, Minh-Man, et al. "Down-sampling based video coding with degradation-aware restoration-reconstruction deep neural network." International Conference on Multimedia Modeling. Springer, Cham, 2020.
[3] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.